该来的,一定会来的
偷懒了大半年,也不是真没什么可说的,有一些零碎的想法就丢日记里面算了,懒得拼凑成文了。 当然,还是可以为偷懒找到一些合理的理由的。比如,以下三个本人认为还是很合理的😎。
- 换了个讨口饭吃的地方。新环境,新硬件,新架构,新技术路线,新软件栈都是需要学习和摸索的,这当然需要花一些精力和时间。另外就是,要想在一个新环境中比较顺畅的做点事情,体现点价值,摸文化,摸山头,摸潜规则,摸政治,摸合作方的手艺,这些都是少不了的非技术性工作,但非常耗费精力。
- 智算大年。从听到的信息看,大家都是聚焦在“智算中心”的项目上的,这种非常考验团队无短板的
big case,要各种知识点都不能有太大问题。要做事不出纰漏,还是要老老实实看点东西,把快丢了的知识再捡回来,这同样需要时间。 - 大模型大年。从去年底开始的
ChatGPT狂热,到大家几乎都认同的模型架构收敛,我是坚信一定会有人去疯狂的做专门针对大模型推理场景的新加速器的,瞎 BB 没用,还是等等看面向大模型会有哪些创意。
放个声明:
本公众号所有文章内容与本人供职单位无关。
打败魔法的,只有魔法
对于下面这个观点,我的坚持是不会变的:
人家有几十年的技术积累,能用到供应商最新的技术,比如
HBM就算没有管制,可以放开买,还是大概率比人家拿到的产能晚一代,还要去兼容人家的护城河CUDA生态,然后还要能性能超越并且TCO碾压人家。这真的不太现实啊,这种想法过于魔幻了。
现实的选择是:要么放弃全面战争(训练、推理、高性能网络),在局部战场(推理)先取得胜利,打下一片根据地,再图谋扩大疆域;要么三分天下有其一,可能能占据的地盘偏远(没极致性能需求)、苦(需要投入大量资源支持)、寒(投入产出比不高),但是起码也是割据一方的天子嘛,悉心经营,开言纳贤,静待实力天平变化。
所以,让我们看看新来的魔法。
吃这碗饭,HotChip2024是怎么都要提一下的,否则显得太业余了。
Maia 100 & Tesla TTPoE
说实话,不管是MI300X、Gaudi 3、SN40L或者是Blackhole都不够让人“虎躯一震”(反正我也不是搞芯片的,主打一个看热闹不嫌事大,但是谁家的图画的好看还是能看出点门道的)。
看到Tesla TTPoE的时候,以我那点羸弱的网络知识,真觉得是有点东西的,而且不是一小点,是非常大的点了。
直到看到Azure Maia 100的 PPT 第一页的时候,真的觉得没瞎等着看热闹。

注意这句话:
Designed specifically for Azure to run production OpenAI models。
一句话里两个专用啊:Azure和production OpenAI models。不负责任的瞎解读猜一下:
从 PPT 里透露的信息看,
Maia 100应该考虑的是两个事情。
- 一个是:
Backend Network的设计是ethernet-based,而且支持direct and switch connectivity,并且Same network for both scale out and scale up,这对于云厂商来说,一方面系统造价省,另一方面能最大限度的利旧,毕竟单口400 gbe这个规格要求并不高,现成的交换机基本都能用。对于ethernet-based的好处和原因,建议看看 同一天Tesla的TTPoE(Tesla Transport Protocolover Ethernet)的 PPT。要进一步消化这个知识点,建议延伸阅读下大网红zartbot的文章HotChip2024后记: 谈谈加速器互联及ScaleUP为什么不能用RDMA。- 另一个是:
ethernet-based backend network with built-in encryption engine,数据加密对于互联网业务怎么强调也不为过,可以对照苹果前几天发布会上怎么介绍Apple Intelligence的Private Cloud Compute在数据安全方面的工作,来理解下数据安全和隐私保护这件事对于云服务厂商代表什么。run production OpenAI models这个不言自明:大概率是OpenAI的那帮人给了在芯片可接受产品生命周期内的承诺:硬件加速就这么搞,我们生产模型结构不会让你们吃惊(显然,研究和开发阶段的模型,显然还是在黄老板的卡上跑了。),算子也不会让你们慌,我们相信sclaling low就可以出奇迹……。
这里面其实有点小小的不太好理解,但是很容易想明白的事情。
看Azure Maia 100PPT的产品介绍,不管是互联、SDK、PyTorch 集成、集合通信、编程模型以及开发、调试工具都是完备的,按照本人过去出去售前念 PPT 的经验,软硬件的介绍已经完备到这个程度了,必然去接着吹讲:我这个软硬件已经完全支持大模型的从头训练、微调和高性能推理了,并且和TGI、vLLM这些推理引擎完成了适配,再顺手秀一点性能数据……balabala。
但,神奇的事情,这个 PPT 说完 SDK 就结束了。多一句都不强调训练和微调能力。
到底是,软件讲的还是“愿景”或者,真的就和 OpenAI 谈好了,就是上 Azure 部署推理集群给他们用,短期不给别的客户用。但,这依然不合理,真只跑推理,软件说那么全没啥用啊。
神奇的世界,看不懂啊,看不懂。
etched Sohu
说面向Transformers模型结构的大模型加速芯片,虽然没去HotChip2024亮相,但是不提一下Sohu是不合适的,毕竟人家放出来的数据是相当炸裂的。
-p-800.png)
单机 8 卡,Llama3 70B,throughput > 500,000 token/s.
8 卡每秒五十万 token 的吞吐啊,哪怕就是 2 bit 量化的😁也挺吓人的,何况人家披露的对比测试配置是:
Benchmarks are for Llama-3 70B in FP8 precision: no sparsity, 8x model parallel, 2048 input/128 output lengths.
想知道更多的细节?
除了144 GB HBM3E之外,等了三个月,什么都没等到,数据是怎么做到的,猜吧……
不管怎么样,这种放在官网的数据还是可信的,在 5 TB/s这个带宽量级下跑出来这种离谱数据,全靠ASIC电路足够硬了。
按照他们的说法:
We can scale up the same trick to run Llama-3-70B with 2048 input tokens and 128 output tokens. Have each batch consist of 2048 input tokens for one sequence, and 127 output tokens for 127 different sequences.
If we do this, each batch will require about
(2048 + 127) × 70B params × 2 bytes per param = 304 TFLOPs, while only needing to load70B params × 2 bytes per param = 140 GBof model weights and about127 × 64 × 8 × 128 × (2048 + 127) × 2 × 2 = 72GBof KV cache weights. That’s far more compute than memory bandwidth: an H200 would need 6.8 PFLOPS of compute in order to max out its memory bandwidth. And that’s at 100% utilization - if utilization was 30%, you’d need 3x more.
2048+128的这个 summarize case,拉着 NVIDIA 和 AMD 一起揍不好吧?大家还记得两边发文章互撕的事情咩🤣?技术人的黑色幽默啊:喂喂喂,说你两呢,别撕了,你们都是弟弟,好意思撕么🤪
他们的大概逻辑是:
H200的带宽是 4.8 TB/s,weights + KV cache 是 212GB,所以这个比例是
22.6,再乘以一次前向的计算需求304 TFLOPs,等于6.8 PFLOPS。
这里有几个有意思的疑惑点,估计还是我太菜,没看懂:
- 算 KV cache的时候
64有点儿不理解。Llama3-70B的config中64是attention heads的数,但是从 Llama2 开始换成GQA了,后面的8应该就是这个。所以,这地方是不是应该是 layers 的:80?有研究过这个细节的朋友,还望赐教,笔芯🫶。- 秀肌肉的
Benchmark用FP8,算帐的时候用FP16,出于何种考虑?
3D DRAM
HBM贵就不说了,钱能解决的事,在芯片这个花钱如流水的行业,不是大事。但和光刻先进制程一样,最先进的是不是给你用,这是个问题。
贵且随时有断供风险的事情,一定需要替代方案,于是 3D DRAM的Hybrid Bonding技术路线,就一定会加快进展。
具体可以看清华团队的这个 paper: Exploiting Similarity Opportunities of Emerging Vision AI Models on Hybrid Bonding Architecture,想偷懒的可以看半导体行业观察的这篇:3D DRAM存算一体架构,清华团队发布。
芯片我不懂,就不瞎逼逼了,大家见仁见智吧。
从计算架构、互联到DRAM,硬件的新魔法看了几个,下面看个软件的魔法吧,毕竟,膳食均衡很重要。
CUDA-Free
看见这个CUDA-Free先不管他到底free了什么,就冲着free就让人觉得神清气爽啊,就问你是不是?
好消息是,这个free是真free了CUDA。来自PyTorch团队的一个工作:CUDA-Free Inference for LLMs。
先看效果,用 纯 Triton kernel 达到了 CUDA kernel 的 8 成性能:
For single token generation times using our Triton kernel based models, we were able to approach 0.76-0.78x performance relative to the CUDA kernel dominant workflows for both Llama and Granite on Nvidia H100 GPUs, and 0.62-0.82x on Nvidia A100 GPUs.
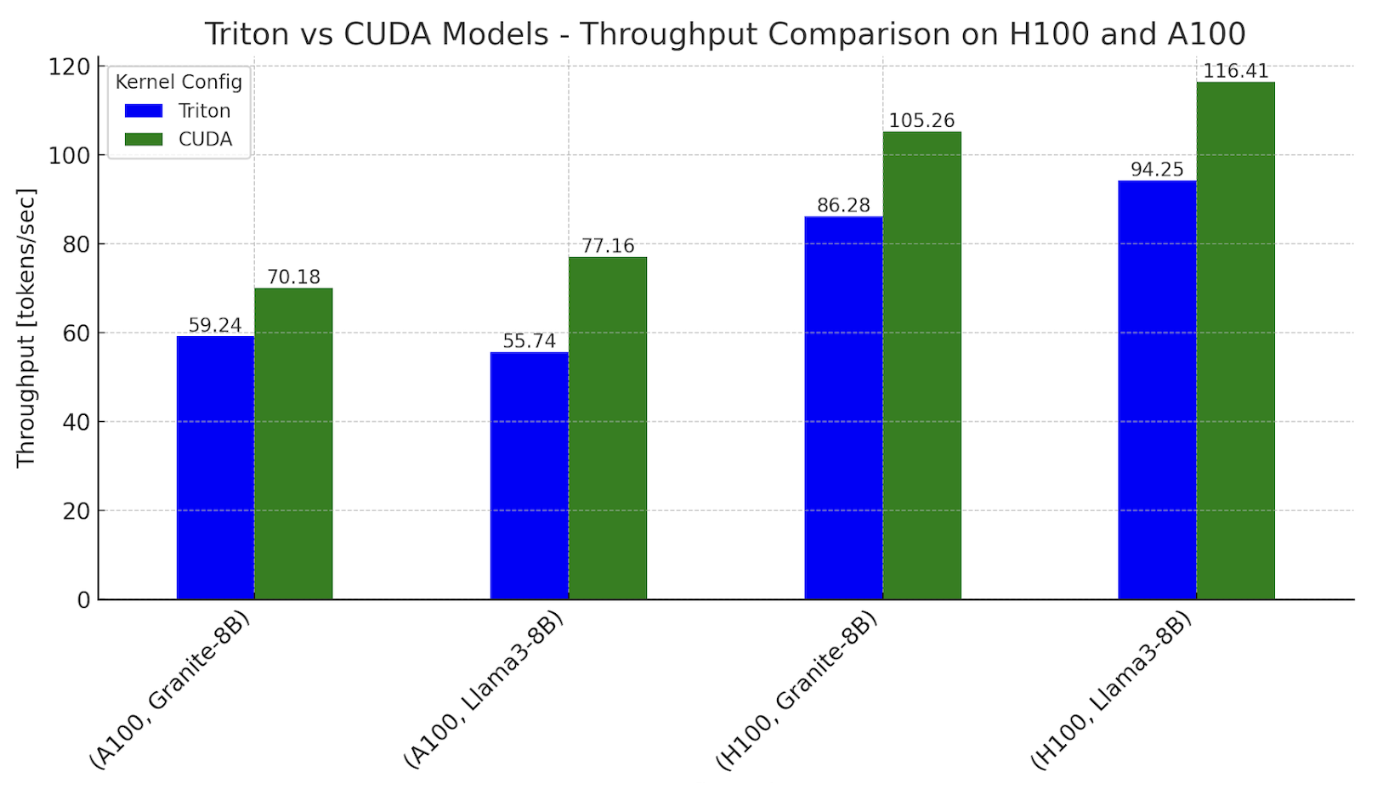
人家也解释了一下为什么去尝试CUDA Free这件事,这事对于我们这些国产 AI 芯片来说,怎么说都不为过啊🙏(嗯,我好像什么都说了,有什么都没说。)
Why explore using 100% Triton?
Triton provides a path for enabling LLMs to run on different types of GPUs - NVIDIA, AMD, and in the future Intel and other GPU based accelerators.
It also provides a higher layer of abstraction in Python for programming GPUs and has allowed us to write performant kernels faster than authoring them using vendor specific APIs.
还没看过的,赶紧去看吧,当然,我显然还会给你提供一个中文版本。
受限于目前隔壁管制的这个局面,A100这张卡,几乎是我们这个行业的 baseline 了,只要有机会,大家都想拿他出来炫一下对比。
所以,请回忆下:
在芯片账面性能不输
A100的情况下,大家手搓 kernel用了多少人、多久,把Llama性能搞到A100八成的。
只能说Triton真的越来越香了啊,相信很快妈妈再也不问我大模型推理能不能兼容 CUDA 的问题了。
DRAM 带宽是一切么?
尽管有些人拿着3~5年前定义的芯片,甚至用LPDDR的,说是大模型专用芯片,甚至还是训推一体,这些其实都无所谓。
不同场景有不同的带宽需求,不是说Groq的那种快就是市场需要的。
正常成年人认真阅读母语的速度,每分钟也就在200~400字这个范围(一目十行那不是阅读),换算过来也就不超过 7 字/s,考虑到Llama系列的tokenizer对中文分词的不太友好的问题,20 token/s 也许就是一个可接受的下限。
不管7/8B、13B还是70B,20 token/s这都是一个非常不高的带宽需求了,做不到的应该不多吧。换句话说,那就是真要做不到,大模型这个市场,可能就不是你的目标市场了。
所以,推理场景,理解客户的场景需求,把并发和首字延迟搞定,流畅稳定的输出,确定一个合理的售价,帮助用户把TCO降下来,比你去宣传有多大带宽可能更有意义。
毕竟,过剩的性能,对正常客户而言,毫无价值。参考下:家轿与超跑,购买力无限的土豪,不在本讨论范围。
所有情怀终会定会回到朴素的商业逻辑
这个,估计标题就能说明所有问题了吧😅😂。
先是一家头一天传出来大动静,第二天就开all-hands,之后全行业都知道了。当然,从市场情况和融资环境来看,这种事情应该也是开始,后面一定还会有融资失败、对赌失败的消息。
在商言商,这是时间到了之后的必然。
然后,两家开始上市辅导的新闻大家都知道了,虽然上市辅导与最终IPO还有相当距离,也不是必然因果关系。
不管是对赌压力还是实力到了,起码有了一个好的信号,对整个行业都是利好。
不Open的OpenAI带来的这一波LLMs的利好和商业机会,可以说是这个行业的及时雨了。
过去,规模性的出货,似乎只有集采一个机会,这个机会最大可能属于谁,大家其实都知道,主打一个参与吧。
模型结构收敛了,PyTorch一统框架江湖了,算子少了,Triton来了,PyTorch 2来了……
市场不需要培育了,客户不需要布道了,性能指标怎么快速评估,几乎简单到了小学数学的计算能力范围……
编程难,不好用,迁移工作量大,这些过去的槽点,现在一个MaaS一招化解……
一体机、智算、大单机会遍地都是了,对国产化的接受和容忍度也达到了一个新的高度……
比CV时代更好商业机会来了,这两年再出不了货,融资也就真别想了,真就有可能要开all-hands宣布点啥了。
是的,该来的,一定会来。